|
fiogf49gjkf0d
Part 2 – Description and explanation
Anyone who have ears and a rudimental mind to understand what ears register, and anyone among them who played with MF channels driven by SET, know that subject of SET loading is imperative.
Let take for instance an average 16R compression driver, loaded into an average horn and driven by let say an average 2A3. The 2A3’t plate will see a load: an impedance of the driver multiplied by the ratio of the 2A3 output transformer. Let say that in our case we do like the sound of our 2A3 loaded to an arbitrary 5kOhm.
At selected 5K we have some kind of a good TTH balance where the driver has the “default” tone and a proper equilibrium between transients and harmonics – this is what we like and how it shall be. Now, let to change the transformer ratio and let our 2A3 to see not 5K but let say 2K. We have more power, more gain, much more extended harmonics and good reduction of transient characteristic. Moving in opposite direction and loading the 2A3 with 10K we will have much faster sound, with more shallow harmonics and with much expedited transient. This is normal. There are many conditions how different compressions drivers, different transformers and different tubes react to the change of loading. In some cases you might load the same 2A3 to as low as 1200R and as high as 16000R and still have acceptable sound, as I said - there are many “depends”. Still, in all cases the balance/conflict between the transient and harmonic is always there.
If you played with it a bit then you know that despite all-together negative result there are some interesting properties in the sound of an overloaded tube. This sound is over-damped, very slow, and almost compressed but it also has some lush qualities at the bottom of the band-pass that I find very appalling. Any overlay idling tube equality unpleasant as it sounds overly paunchy with no tonal values. However even in this sound of uncontrollable diaphragm flapping there are some positive moments – dynamics and transients. Interesting that the way how drivers react to all of it is built into the drivers design and more or less stay with the driver. The type of the cone, the type of suspension, the type of magnets, contra-pressure zone from back and front, the type of compression and damping – all of it, and many other aspects affect when this particular driver start fracture sound apart in case of idling or start howl like a wolf in case of overloading. Did it even come to you that it would be very cool if THE VERY SAME DRIVER would have lash harmonics and tone of an over-damped driver and at the same time the transients and dynamics of an idling driver?
Well, if you look the progress of my audio practice over the course of the last few years: Injection Channels, re- shaping the harmonics of individual channel by independent DSET loading... then the solution might logically flow. What I propose is to use a COMPOSITE MF CHANNEL that consists of TWO MF drivers. This way we cold put one ass on the two stools and to take advantage of the idling AND over-damped driver. Let see how it might be gone practically. Above I have mentioned our proverbial 16R compression driver that does well loaded into 5K. Take second identical driver like this and convert the back side of your MF horn into something that accommodates dual drivers. I am not talking about the Renkus-Heinz or Tom Danley multiple entry horns but rather about a very simple dual-driver single throat scenario. Do you remember the JBL 2329, 30170, 30172 dual adapters? Something like this only preserving the proper shape of the transition curve from multiple throats to a single composite throat.

So, two good drivers are loaded to the same throat and each driver is driven by own individual let say DSET. The first driver is driven by DSET loaded to 2K and the second driver driven by DSET loaded to 15K. The DSET that loaded to first driver has an attenuator that rolls off excessive gain. The DSET that loaded to second driver has output tube with enough gain to drive the 15K load. Both of the DSETs are driver from one filter or from own filters, still they are driven by the same signal. Now, changing the driving characteristics between the first and second drivers we can vary what the final harmonics -transient balance of the channel, extending the capacity of ANY MF driver. Pay attention I said: “driving characteristics” not just “changing the volume” between the drivers. Since they are compression drivers loaded into the same throat I stipulate that a final mix of the total pressure from each drive have to be ROUGHLY the same. Furthermore, I am pretty sure that the “over-dumped” driver will inflict some front channel damping to the “idled” driver, that is fine and we do not care about the absolutely damping anymore for an individual driver but we care only about composite result of the entire MF channel.
So, what we did was implementing sort of Harmonic-Transients Corrector that can extend capacity of any driver. This itself, is a phenomenally powerful tool in my view, that offers a lot of control over how MF sound. Moderating the driver’s volume to a degree, the type of the amplification the drivers used, the type and the ratio (loading) of the output transformers and many other parameters of individual drivers we has unparalleled control other the multitude characteristics of our composite MF driver. That itself is amazing opportunity for somebody who have a sense HOW SOUND SHALL SOUND, which pretty much eliminated 99.9% of all audio hoodlums. If you are within that tiny group of people who has judiciousness and understanding about want they want from Sound then be advised that what I described above is not my AMI™ Concept but is something that might be called the UAMI Concept, or the “Unintelligent-AMI”. For you, the fraction of those who have more evolved objectives, I will continue.
“AMI” stands from “Active Midrange Insertion”. I guess at this point from my explanation above you have an idea how I propose to conduct the MF Insertion, now I need to explain the “Active” part of that notion.
A trumpet, an oboe, or the entire orchestra play loud or play soft. Did you pay attention to the pattern between volume of the sound and the sound harmonic context? You might argue that harmonic context shall be proportionally-stable across the whole dynamic range or shall changed according to some rules. I do not know the correct answer but I know it exist under given specific conditions. I would equally discard anybody insistence that they have am fixed universal grip of volume/harmonic as balance as I feel that our ways to measure/analyze harmonics (and harmonics distortions) are fundamentally faulty. The purely- mathematical and unconditional representation of harmonics distortions is absolutely worthless and it contradicts the Gödel's both Incompleteness Theorems. I have a long theory about it and I will not dive into it at this point. I just would say that my observation of HOW audio people USE their understanding of harmonics is completely irrelevant to the actuality of Sound. I would admit that there is SOME pattern according to which loudness and harmonics changes. We do not know the pattern; do not know that condition under wish the pattern changes and we have not too much PROPER ways to manage the pattern even if we do know the rules. Yep, but now we have built out above-described UAMI™ machine, let take it one step further.
Let visualize the UAMI™ concept. Let start from the re-naming. The driver that is driven by overdamped amp we will call the “Harmonics Server”. The driver that is driven by over-idled amp we will call the “Transients Server”. Mind you that it might be not only 2 driver but 3 drivers if you wish or more BUT it will be always Harmonics Servers and one Transients Servers. Let pretend that the Harmonics Server and Transients Server connected to source via individual attenuator and we have somebody who very slightly changes the mix of Harmonics and Transients depends of the signal volume…. You see where I am doing? Now we have a mechanism that completely decouples Harmonics from Transients, getting rid the proverbial Harmonics/Transients push-pull. Now, replace that “somebody” with a programmable algorithm and we have a mechanism that can ACOUSTICALLY mimic the Harmonics /Transients/ Volume pattern of live sound. This is sound reproduction at very different level.
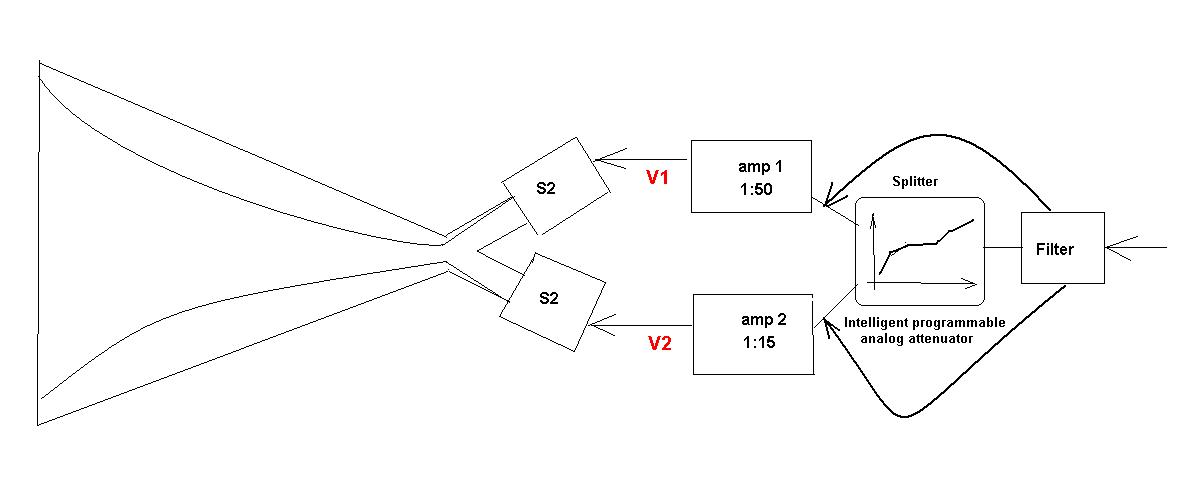
So, here is how I invision it in the end. We have a MF driver that consists of a cluster of individual drivers with well defined Transients Server and Harmonics Server duty. The drivers are driven by a cluster of amps or at least 2 amps to subside the intermodulations. Each amp is connected to analog Real-Time Mixer-Analyzer (RTMA), – some type of chip that might pad down individual output with respect to external logic. The RTMA reads the signal via a microphone analyzes the dynamic range, frequency and makes a decision what shall be the mix between the Transients Servers and Harmonics Servers for a given room acoustic. So, you installed the playback, read with RTMA the sound of your room and RTMA print on screen some kind of parabola that is recommend for the given MF driver cluster and the given room. Then you do what you do in Photoshop when you adjust density curves - manually bend the parabola, affecting the pattern in which the Transients and Harmonics relate to volume. Pay attention that a distraction of Sound by DSP is not in the picture and sound to each amp still flows just across a single programmable analog resistor. The Transients and Harmonics relation in this case is set like it set in live sound – by vibration subject on air in different ways. This is what I call the AMI – the Active Midrange Insertion.
The ideas above give a lot of food for thoughts for somebody who have thoughts. The Harmonic-Transients Corrector (UAMI) is very simple to implement and I have no idea what such a thing never was used. Still, the full-blown AMI would be an ultimate objective as I feel it might make reproduced sound to behave like live sound. With total maximum dynamic range let sat 112dB and properly configured AMI it might be it. I intentionally stressed MF only as I think it is a key to everything. Feel free to expend upon the ideas proposed above and shall any of you would like to experiment with the full-scope AMI then contact me. I did some thinking about it and had a few further ideas how it might work and how some derivatives from the AMI idea be used. Rgs,
Romy The Cat
|